Schriftart - Tastatur - Zeichensatz:
Viele Computeranwender kennen nur unterschiedliche Schriftarten, wie z.B. ein
Text
Text
Text
Text
Text
auf dem Bildschirm oder auf dem Drucker dargestellt wird.
Daß es unterschiedliche Tastaturen gibt, wird oft erst bemerkt, wenn man in einem anderen Land einen Computer nutzt,
und z.B. ein "ä" vermißt.
Unter einem Zeichensatz können sich die meisten Anwender nichts vorstellen,
z.B. ISO 8859-01 oder UTF-8.
Schriftart (Font):
Die Schriftart bzw. der Font definiert, wie Text auf dem Bildschirm oder Drucker angezeigt wird, Beispiele:
Arial ,
Calibri ,
Times new Roman .
Zusätzlich kann man definieren, ob der Text fett oder kursiv sein soll,
wie groß bzw. mit welcher Farbe die Anzeige erfolgen soll, und noch mehr ...
Viele der bekannten Schriftarten können nur die Standard-Zeichen, die meist auch auf der Tastatur zu finden sind, und einige Sonderzeichen darstellen.
Mittlerweile gibt es aber viele zusätzliche Zeichen, wie z.B. Smileys (😁 😉 😠 😸),
welche die meisten Schriftarten nicht enthalten und meistens durch Schmierzeichen (⎕ ▒) dargestellt werden.
Aktuelle Webbrowser beherrschen die meisten Sonderzeichen, darum sind diese oben auch dargestellt, aber in den Text-Editoren werden
standardmäßig nur die üblichen Windows-Fonts bzw. Adobe-Fonts verwendet, welche nur wenige Sonderzeichen darstellen können.
Man kann im Internet aber spezielle Fonts runterladen und im Betriebssystem installieren, um mehr Sonderzeichen darstellen zu können,
z.B. den Font Symbola
↠ runterladen ↠ symbola.ttf ↠ rechte Maustaste ↠ öffnen mit ↠ Windows Schriftartenanzeige ↠ installieren.
Diese Schriftart dann im Texteditor der Wahl einstellen, z.B. bei Notepad++ unter ↠ Einstellungen ↠ Stile ↠ Symbola ↠ speichern
Diese Schriftart ist nicht schön, aber zum Testen der Sonderzeichen brauchbar.
Eine Sammlung von Smileys (Emoticons) gibt es hier.
Wichtig: Zeichen, die in der ausgewählten Schriftart nicht enthalten sind, können nicht dargestellt werden!
Tastatur:
Die Tastaturen sind länderspezifisch und enthalten jene Zeichen, die in der entsprechenden Sprache am meisten benötigt werden.
Diakritische Zeichen, wie z.B. das é,
werden evtl. auch durch Tastenfolgen eingegeben (´ e).
Weitere Möglichkeiten hat man mit virtuellen Tastaturen, evtl. mit Touch-Screen-Unterstützung.
Beispiel für einfache virtuelle Tastatur, den Text in den Editor der Wahl kopieren.
Zeichensatz:
Der Zeichensatz ist die Regel, nach der Zeichen im Speicher des Computers abgelegt werden.
Je nach Zeichensatz kann z.B. ein ä als Byte E4
oder als Byte-Kombination C3 A4 abgespeichert werden.
Einfache (alte) Zeichensätze konnten nur 192 verschiedene Zeichen darstellen.
Daher mußte man je nach Sprache einen passenden Zeichensatz wählen.
Wichtig: Zeichen, die in dem ausgewählten Zeichensatz nicht enthalten sind, können nicht gespeichert werden!
Wenn man ein Dokument ansehen oder bearbeiten will, muß man also wissen, welcher Zeichensatz verwendet wurde, und diesen eistellen.
Moderne Zeichensätze wie UTF-8 können automatisch erkannt werden, da am Dokumentenanfang eine entsprechende Codierung hinterlegt ist, das sog. BOM.
Heute wird fast nur mehr der Zeichensatz UTF-8 verwendet, der praktisch alle vorkommenden Zeichen darstellen kann.
Wie editiert man nun Zeichen, die nicht auf der Tastatur enthalten sind ?
Am einfachsten geht es mit Hilfe des kostenlosen Programmes Babelmap.
Runterladen ↠ entpacken ↠ aufrufen (keine Installation notwendig) ↠ die Bedienung ist selbsterklärend !
Beispiel: das Smiley 😁 wird durch die Byte-Kombination F0 9F 98 81 abgespeichert.
Es werden je nach Zeichen bis zu 4 Bytes benötigt, aber was ist denn nun ein Byte, weiterlesen .....
Einige Informationen zum Verständnis: Was ist ein Byte ?
Ein Computer speichert Daten in digitaler Form, wobei die kleinste Einheit 1 Bit ist.
Mit so einem Bit kann man nicht allzuviel anfangen, daher faßt man 8 Bits zu einem Byte zusammen.
Diese 8 Bits eines Bytes haben die Wertigkeiten:
128 | 64 | 32 | 16 | 8 | 4 | 2 | 1
Mit einem Byte kann man daher dezimale Werte von 0 ... 255 abbilden, binär dargestellt: 00000000 ... 11111111
Es ist noch eine weitere Darstellung üblich, wobei man 2 Gruppen zu je 4 Bits bildet: 0000 0000 ... 1111 1111
Diese 4 Bits eines sog. Nibbles haben die Wertigkeiten:
8 | 4 | 2 | 1 ,
damit kann man Werte von 0 ... 15 abbilden.
Die Werte 11 ... 15 schreibt man aber als A ... F (a ... f), man zählt also:
1|2|3|4|5|6|7|8|9|A|B|C|D|E|F
Den Wertebereich eines Bytes kann man also wie folgt darstellen:
-
00000000 ... 11111111 Binäre Darstellung
Beispiel: 'z' = 01111010
-
00 ... FF Hexadezimale Darstellung
Beispiel: 'z' = 7A
-
00 ... 255 Dezimale Darstellung
Beispiel: 'z' = 122
Der US-ASCII Zeichensatz: 1 Byte speichert 1 Zeichen

Schon in der "Computer-Steinzeit (~1965)" hat man Ziffern und Buchstaben im Computer gespeichert.
Allerdings hatte man nicht alle 8 Bits eines Bytes zur Verfügung, ein Bit benötigte man zur Sicherung
für die Übertragung von Daten über Telefonleitungen.
Weiters benötigte man 32 Werte (00 ... 1F) zur Abbildung von diversen Steuerzeichen, wie z.B. den Wert 0A für LF (neue Zeile).
Der Zeichenvorrat reicht für englische Texte, aber es fehlen regionale Sonderzeichen,
wie z.B. deutsche Umlaute, und es gab nur ganz wenige Symbole.
Da hat man sich früher beholfen, indem man
Wenn man sich auf die Zeichen dieses Zeichensatzes beschränkt hat man aber auch einen Vorteil:
Egal, welcher Zeichensatz verwendet wird, die Anzeige wird immer korrekt sein, da diese Zeichen in allen Zeichensätzen identisch sind!
Westeuropäische MS-DOS und Windows-Zeichensätze:

Im "Computer-Mittelalter (~1990)" verwendete man schon
Die untere Hälfte ist immer identisch dem US-ASCII-Zeichensatz, in der oberen Hälfte werden regionale Sonderzeichen dargestellt.
Man muß also den für die jeweilige Region vorgesehenen Zeichensatz wählen, und hat dann auch nur diesen Zeichenvorrat zur Verfügung.
Eine Besonderheit der Windows-Zeichensätze ist, daß auch der obere Steuerzeichenbereich von 80 ... 9F für Sonderzeichen
verwendet wird, ansonsten ist der Windows 1252 Zeichensatz identisch dem ISO 8859-01.
Der im Rechner eingestellte Zeichensatz muß auf die Tastatur abgestimmt sein.
Westeuropäische ISO 8859-## Zeichensätze:
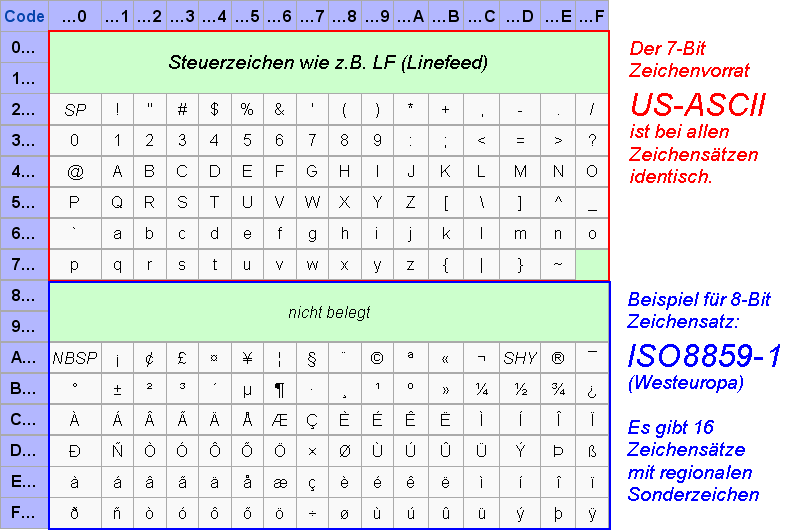
Mit der Einführung des Internets wurden die Zeichensätze weltweit bei ISO genormt.
Um alle Regionen abzudecken waren 16 Zeichensätze erforderlich: ISO 8859-1 ... ISO 8859-16.
Man muß also den für die jeweilige Region vorgesehenen Zeichensatz wählen, und hat dann auch nur diesen Zeichenvorrat zur Verfügung.
Ist jemandem aufgefallen daß das Euro Symbol
Wenn man HTML-Seiten erstellt steht der Zeichensatz im Header:
<charset="utf-8"> (ab HTML5)
<meta http-equiv="content-type" content="text/html;
charset=ISO 8859-1">
Webbrowser (HTML) ermöglichen es jedoch auch Zeichen eines anderen Zeichensatzes als benanntes Zeichen zu verwenden (€ = €).
Aktuelle weltweit einsetzbare Unicode Zeichensätze, z.B. UTF-8:
Unicode ist ein internationaler Standard, bei dem für jedes Schriftzeichen oder Textelement aller bekannten Schriftkulturen
und Zeichensysteme ein digitaler Code festgelegt wird, damit entfällt die Notwendigkeit einen spezifischen Zeichensatz zu laden
und der internationale Datenaustausch wird erheblich erleichtert.
Unicode umfaßt 17 Bereiche zu je 65.536 Zeichen, also insgesamt 1.114.112 Zeichen, derzeit sind 100.713 Zeichen belegt.
Jedes Unicode-Zeichen hat eine eindeutige Unicode-Nummer: U+0000 bis U+10FFFF (hexadezimal)
Wir kommen in der Regel mit der ersten Ebene aus, also dem Bereich von U+0000 bis U+FFFF.
UTF, das Unicode Transformation Format, ist eine Methode, Unicode-Zeichen auf Folgen von Bytes abzubilden.
- UTF-32 kodiert ein Zeichen stets mit vier Bytes und benötigt daher dem meisten Speicherplatz. (Anwendung ?)
- UTF-16 ist das älteste Kodierungsverfahren, bei dem 2 oder 4 Bytes zur Kodierung eines Zeichens verwendet werden.
-
UTF-8 kodiert ein Unicodezeichen in 1 bis 4 Bytes.
Der ASCII-Zeichensatz wird in nur 1 Byte kodiert!
Damit wird bei auf dem lateinischen Alphabet basierenden Schriften am effizientesten mit dem Speicherplatz umgegangen.
Beispiele für einige Zeichen:

Ob das entsprechende Unicode-Zeichen auch tatsächlich am Bildschirm erscheint, hängt davon ab, ob die verwendete Schriftart eine Glyphe (Grafik) für die gewünschte Zeichennummer enthält.
Bitte beachten: UTF-8 Dateien haben am Anfang evtl. 3 Sonderzeichen zur eindeutigen Identifizierung: EF BB BF, das UTF-8 BOM.
Mir ist eine Situation bekannt wo das stört: bei PHP-Dateien, diese also als UTF-8 ohne BOM abspeichern, gute Text-Editoren können das.
Besonderheiten bei HTML, XML, XHTML:
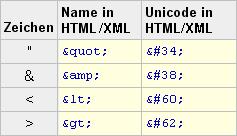
HTML, XML und XHTML unterstützen Unicode mit Zeichencodes, die unabhängig vom eingestellten Zeichensatz
Die Notation lautet &#????; (dezimal) bzw. &#x????; (hexadezimal), wobei ???? die Unicode-Nummer (U+????) des Zeichens darstellt.
Zeichen, die Teile der Auszeichnungssprache sind, müssen durch benannte Zeichen oder Unicode Zeichen definiert werden (Tabelle links).
Viele Zeichen, die nicht im eingestellten Zeichensatz enthalten sind, können bei HTML durch benannte Zeichen dargestellt werden, Beispiele:
- € bei ISO 8859-1: €
- ä bei US-ASCII: ä
- ∑ bei ISO 8859-1: ∑
Empfehlung: Alle neuen HTML-Dateien nur mehr mit dem Zeichensatz UTF-8 erstellen
Wenn als Zeichensatz beim Editieren bzw. Abspeichern der Datei UTF-8 verwendet wird, und im Header der Datei auch UTF-8 als Zeichensatz
angegeben ist,
Es dürfen alle Zeichen mit Ausnahme von &, >, < und " direkt im Text verwendet werden!
Wie editiert man nun aber Zeichen, die nicht auf der Tastatur sind ?
Natürlich kann man nach wie vor die benannten HTML-Zeichen verwenden, man kann aber auch die Unicode-Nummer ermitteln und eingeben.
Unter Windows klappt das mit der Zeichenfolge auf dem Nummernblock:
Es ist zu beachten daß die Unicode-Nummer nicht mit der bei UTF-8 abgespeicherten Zeichenfolge identisch ist!
Am einfachsten geht es mit Hilfe des kostenlosen Programmes Babelmap.
Runterladen ↠ entpacken ↠ aufrufen (keine Installation notwendig) ↠ die Bedienung ist selbsterklärend !
Man sucht das gewünschte Zeichen und kopiert den Zeichencode in den Texteditor.
Die Unicode-Nummer von Zeichen, die man öfters benötigt, kann man sich notieren. Oder noch einfacher,
man speichert diese Zeichen in einer Textdatei und kopiert diese bei Bedarf.
Es soll noch erwähnt werden daß es auch unter Windows ein ähnliches Programm gibt: charmap.exe.
Hier gibts eine Testdatei mit einigen UTF-8 Zeichen direkt im Text.
Resumée: Das Zitieren von Umlauten und Sonderzeichen kann zukünftig entfallen,
wenn man's richtig macht :-)
Virtuelle Tastaturen in diversen Sprachen
Wenn man weiß in welcher Sprache das gewünschte Zeichen vorkommt kann man sich mit einer Virtuellen Tastatur behelfen.
Anmerkungen an Peter